Scheduler¶
The CAF runtime maps N actors to M threads on the local machine. Applications built with CAF scale by decomposing tasks into many independent steps that are spawned as actors. In this way, sequential computations performed by individual actors are small compared to the total runtime of the application, and the attainable speedup on multi-core hardware is maximized in agreement with Amdahl’s law.
Decomposing tasks implies that actors are often short-lived. Assigning a
dedicated thread to each actor would not scale well. Instead, CAF includes a
scheduler that dynamically assigns actors to a pre-dimensioned set of worker
threads. Actors are modeled as lightweight state machines. Whenever a waiting
actor receives a message, it changes its state to ready and is scheduled for
execution. CAF cannot interrupt running actors because it is implemented in user
space. Consequently, actors that use blocking system calls such as I/O functions
can suspend threads and create an imbalance or lead to starvation. Such
“uncooperative” actors can be explicitly detached by the programmer by using the
detached spawn option, e.g., system.spawn<detached>(my_actor_fun).
The performance of actor-based applications depends on the scheduling algorithm in use and its configuration. Different application scenarios require different trade-offs. For example, interactive applications such as shells or GUIs want to stay responsive to user input at all times, while batch processing applications demand only to perform a given task in the shortest possible time.
Aside from managing actors, the scheduler bridges actor and non-actor code. For this reason, the scheduler distinguishes between external and internal events. An external event occurs whenever an actor is spawned from a non-actor context or an actor receives a message from a thread that is not under the control of the scheduler. Internal events are send and spawn operations from scheduled actors.
Policies¶
The scheduler consists of a single coordinator and a set of workers. The coordinator is needed by the public API to bridge actor and non-actor contexts, but is not necessarily an active software entity.
The scheduler of CAF is fully customizable by using a policy-based design. The
following class shows a concept class that lists all required member
types and member functions. A policy provides the two data structures
coordinator_data and worker_data that add additional
data members to the coordinator and its workers respectively, e.g., work
queues. This grants developers full control over the state of the scheduler.
struct scheduler_policy {
struct coordinator_data;
struct worker_data;
void central_enqueue(Coordinator* self, resumable* job);
void external_enqueue(Worker* self, resumable* job);
void internal_enqueue(Worker* self, resumable* job);
void resume_job_later(Worker* self, resumable* job);
resumable* dequeue(Worker* self);
void before_resume(Worker* self, resumable* job);
void after_resume(Worker* self, resumable* job);
void after_completion(Worker* self, resumable* job);
};
Whenever a new work item is scheduled—usually by sending a message to an idle
actor—, one of the functions central_enqueue,
external_enqueue, and internal_enqueue is called. The
first function is called whenever non-actor code interacts with the actor
system. For example when spawning an actor from main. Its first
argument is a pointer to the coordinator singleton and the second argument is
the new work item—usually an actor that became ready. The function
external_enqueue is never called directly by CAF. It models the
transfer of a task to a worker by the coordinator or another worker. Its first
argument is the worker receiving the new task referenced in the second
argument. The third function, internal_enqueue, is called whenever
an actor interacts with other actors in the system. Its first argument is the
current worker and the second argument is the new work item.
Actors reaching the maximum number of messages per run are re-scheduled with
resume_job_later and workers acquire new work by calling
dequeue. The two functions before_resume and
after_resume allow programmers to measure individual actor runtime,
while after_completion allows to execute custom code whenever a
work item has finished execution by changing its state to done, but
before it is destroyed. In this way, the last three functions enable developers
to gain fine-grained insight into the scheduling order and individual execution
times.
Work Stealing¶
The default policy in CAF is work stealing. The key idea of this algorithm is
to remove the bottleneck of a single, global work queue. The original
algorithm was developed for fully strict computations by Blumofe et al in 1994.
It schedules any number of tasks to P workers, where P
is the number of processors available.
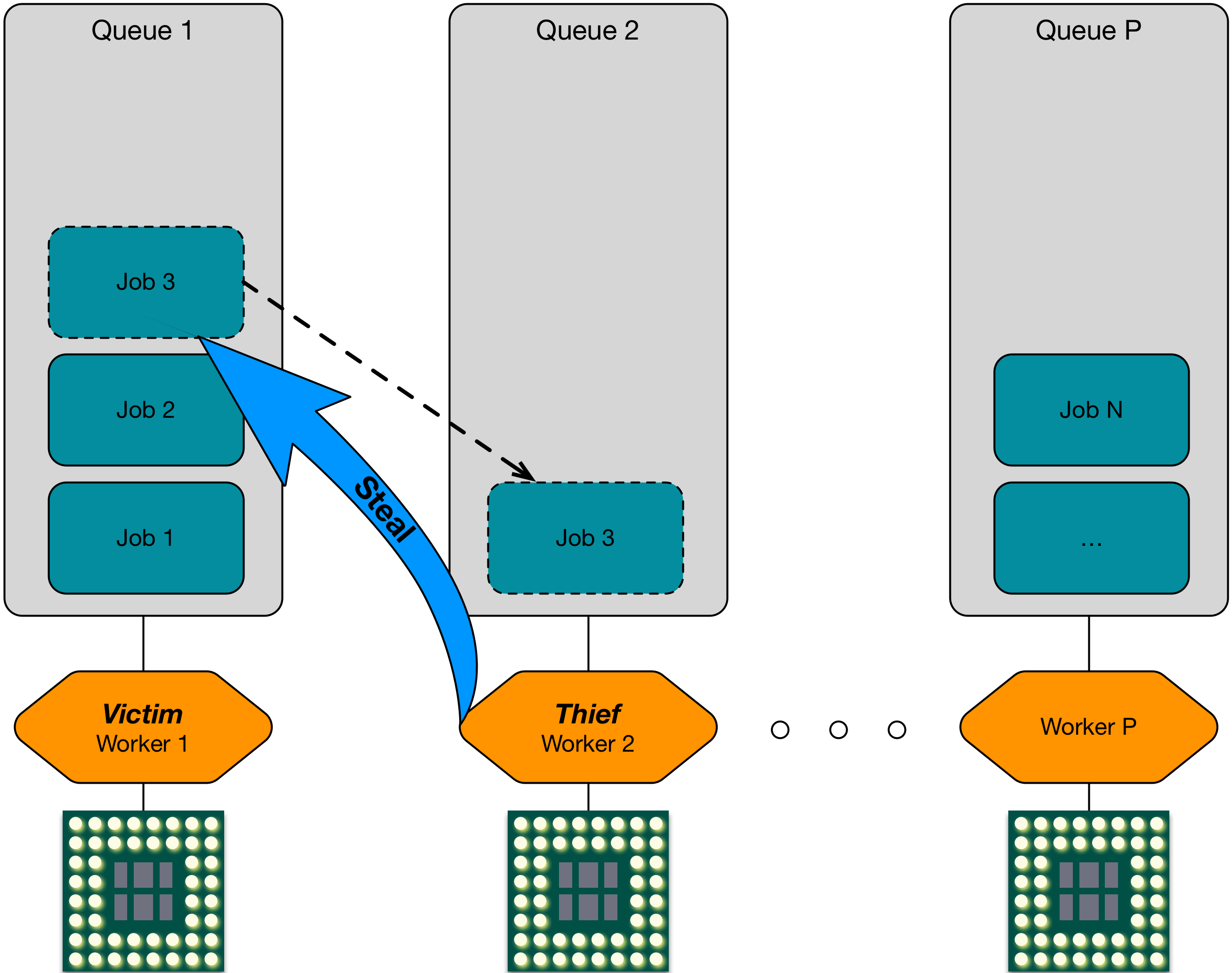
Each worker dequeues work items from an individual queue until it is drained. Once this happens, the worker becomes a thief. It picks one of the other workers—usually at random—as a victim and tries to steal a work item. As a consequence, tasks (actors) are bound to workers by default and only migrate between threads as a result of stealing. This strategy minimizes communication between threads and maximizes cache locality. Work stealing has become the algorithm of choice for many frameworks. For example, Java’s Fork-Join (which is used by Akka), Intel’s Threading Building Blocks, several OpenMP implementations, etc.
CAF uses a double-ended queue for its workers, which is synchronized with two spinlocks. One downside of a decentralized algorithm such as work stealing is, that idle states are hard to detect. Did only one worker run out of work items or all? Since each worker has only local knowledge, it cannot decide when it could safely suspend itself. Likewise, workers cannot resume if new job items arrived at one or more workers. For this reason, CAF uses three polling intervals. Once a worker runs out of work items, it tries to steal items from others. First, it uses the aggressive polling interval. It falls back to a moderate interval after a predefined number of trials. After another predefined number of trials, it will finally use a relaxed interval.
Per default, the aggressive strategy performs 100 steal attempts with no sleep interval in between. The moderate strategy tries to steal 500 times with 50 microseconds sleep between two steal attempts. Finally, the relaxed strategy runs indefinitely but sleeps for 10 milliseconds between two attempts. These defaults can be overridden via system config at startup (see Configuring Actor Applications).
Work Sharing¶
Work sharing is an alternative scheduler policy in CAF that uses a single, global work queue. This policy uses a mutex and a condition variable on the central queue. Thus, the policy supports only limited concurrency but does not need to poll. Using this policy can be a good fit for low-end devices where power consumption is an important metric.